
mBlock è una piattaforma per il coding estremamente ricca, che offre moltissime opportunità di sviluppo di progetti a tutti i livelli di complessità. Si presenta come una valida alternativa a Scratch e amplia le possibilità su alcuni fronti: oltre alla grande quantità di estensioni di cui dispone, mBlock supporta diverse piattaforme hardware (in particolare alcune delle più comuni schede elettroniche utilizzate in ambito educativo, come Arduino, CyberPi o mBot) che possono essere programmate con notevole immediatezza grazie al linguaggio a blocchi, esteso con funzionalità specifiche per ciascuna piattaforma.
Classificare immagini
Una delle estensioni di mBlock si chiama Teachable Machine. Si tratta dell’interfaccia per integrare il noto applicativo di casa Google (Teachable Machine, appunto), che implementa una rete neurale e dunque degli algoritmi per l’apprendimento automatico (il cosiddetto Machine Learning). Nella sua versione più recente, lo strumento consente di classificare immagini caricate da file o da webcam, brevi audio oppure le pose di persone in immagini da file o da webcam. L’estensione di mBlock al momento consente l’addestramento della Teachable Machine solamente allo scopo di classificare immagini provenienti da una webcam collegata al PC. Si tratta quindi di utilizzare uno strumento in grado di associare autonomamente una categoria di immagini preimpostata alla scena inquadrata dalla webcam. Ciascuna categoria viene individuata e caratterizzata durante la cosiddetta fase di training della rete neurale.
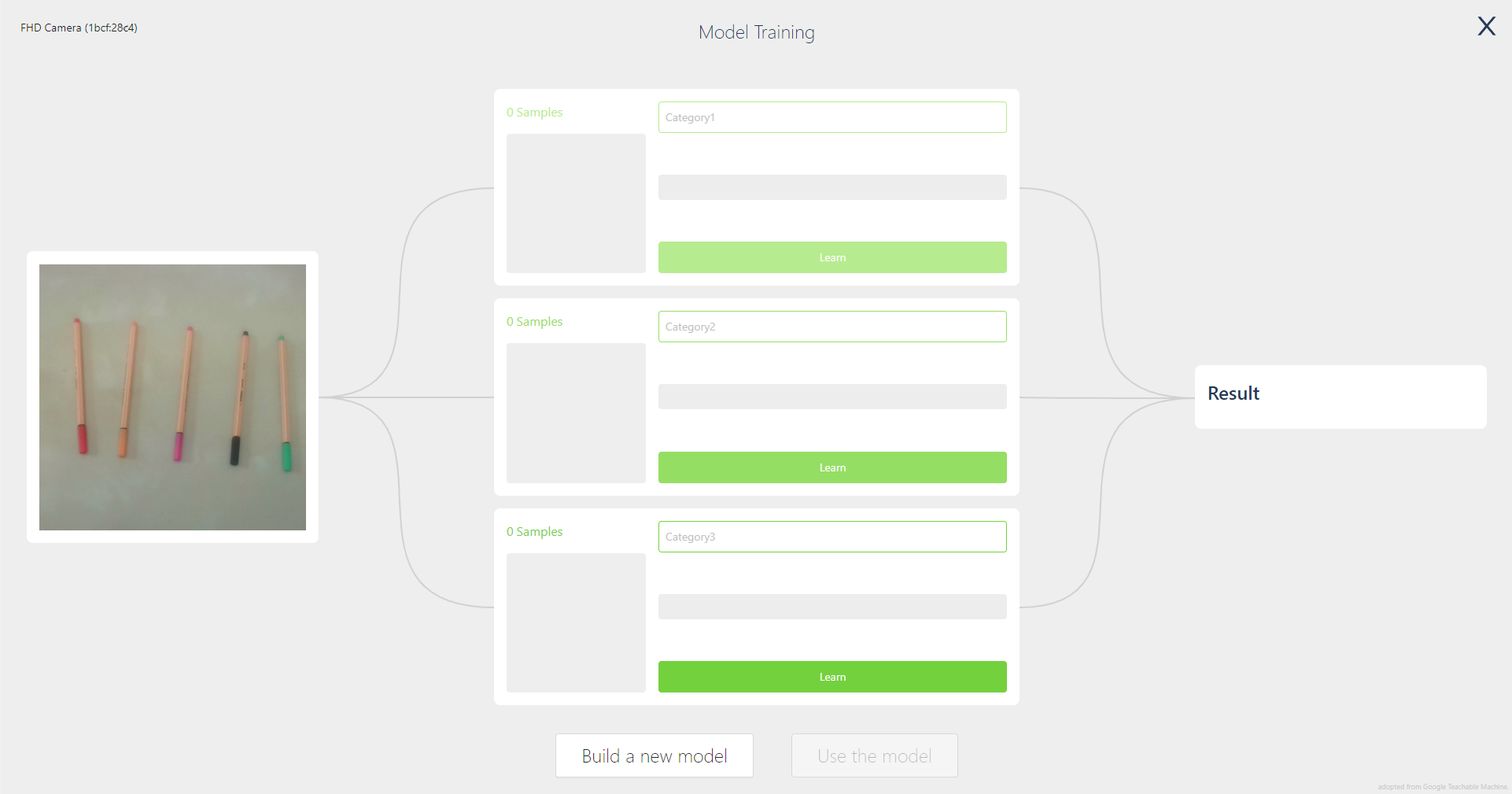
L’interfaccia per la fase di training della Teachable Machine si presenta come in figura: sulla sinistra l’immagine presa in diretta dalla webcam, al centro tre categorie inizialmente senza nome (che andrà specificato) in attesa della registrazione di alcuni dati e sulla destra la zona in cui viene visualizzato il risultato della classificazione dell’immagine che proviene dalla webcam in ogni istante.
Per l’addestramento della rete neurale implementata nella Teachable Machine è necessario anzitutto decidere il numero di categorie in cui classificare gli input (il programma propone inizialmente 3 categorie, ma se ne possono avere fino a un massimo di 30). A ciascuna di esse deve essere assegnato un nome e un certo numero di immagini “di esempio” (il cosiddetto training set) che ritraggono gli oggetti o le scene che fanno parte della categoria stessa. L’algoritmo infatti “impara” come sono fatti gli oggetti facenti parte di una certa categoria proprio sfruttando le informazioni fornite nel training set, che deve pertanto essere vario a sufficienza da poter distinguere con una buona accuratezza immagini appartenenti a categorie distinte e quindi contenere anche un numero sufficientemente elevato di immagini.
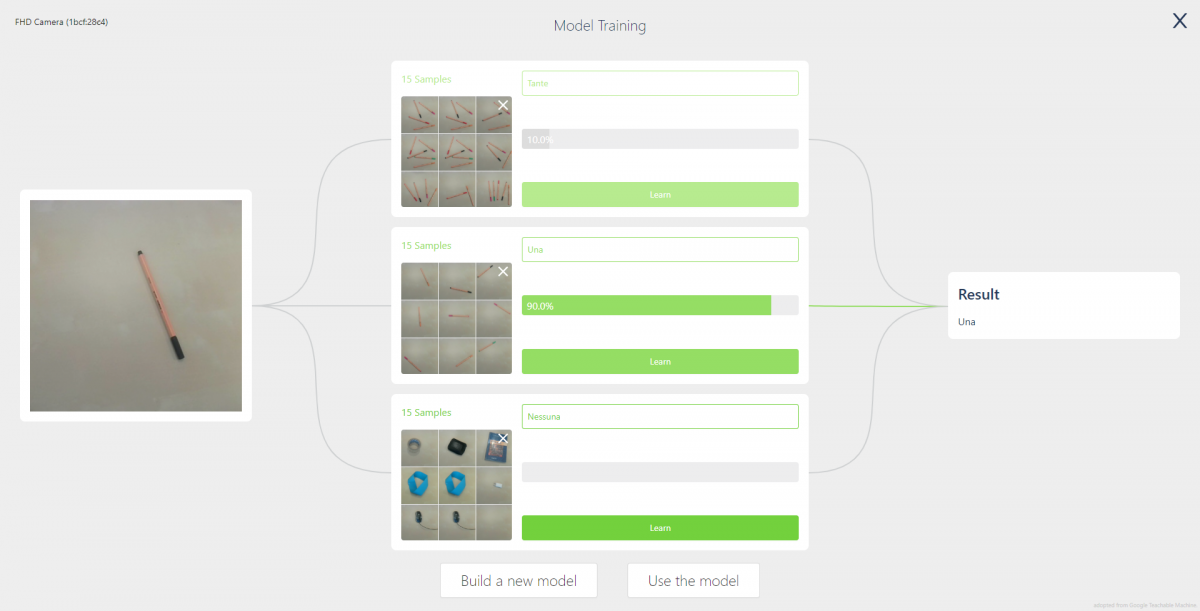
In figura, una rete neurale allenata a classificare le immagini in quelle con più di una penna, quelle con una penna sola o quelle con nessuna penna. Per ciascuna categoria sono state fornite 15 immagini di esempio (un numero certamente esiguo). Sulla destra la classificazione dell’immagine a sinistra, presa in diretta dalla webcam.
Overfitting e underfitting
La fase di training è certamente quella più importante e delicata, perché richiede di bilanciare esigenze opposte e trovare il giusto equilibrio.
Se si forniscono poche immagini o informazioni, la rete neurale non sarà in grado di distinguere bene gli oggetti o le scene inquadrate perché non avrà una rappresentazione sufficiente della complessità degli oggetti. Si parla in questo caso di underfitting. Inoltre la presenza di sfondi o potenziali oggetti intrusi assieme a quelli da riconoscere potrebbe inficiare il riconoscimento. Un corretto riconoscimento è infatti tanto migliore quanto più ogni nuova immagine aggiunta al training set fornisce informazioni “aggiuntive” sugli oggetti che fanno parte della categoria.
Si potrebbe allora pensare che sia bene fornire un elevatissimo numero di immagini di esempio. Le insidie del superare un certo numero di immagini sono almeno due. Da un lato il costo computazionale: tante immagini richiedono tanto tempo per essere processate e ci si rende presto conto che un numero troppo elevato rende ingestibile il training. Dall’altro lato c’è il rischio di overfitting: se infatti forniamo troppi dati relativi a un numero limitato di esempi e di contesti, la rete neurale imparerà a riconoscere come caratterizzanti della categoria anche eventuali dettagli indesiderati di quegli oggetti, che non sono caratteristiche della categoria ma solamente dell’esempio specifico.
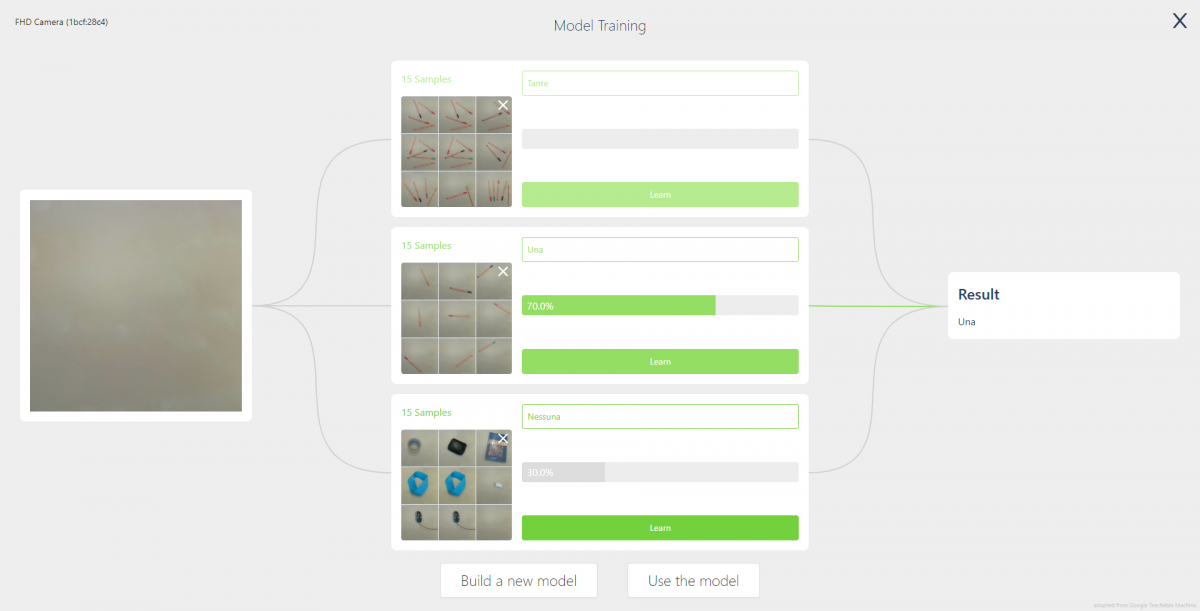
In figura, la rete neurale non riconosce la categoria corretta: dovrebbe riconoscere la categoria “Nessuna” ma invece l’algoritmo classifica “Una” con il 70% di confidenza, pur avendo avuto come esempio per la categoria “Nessuna” anche l’inquadratura dello sfondo senza oggetti. Una delle spiegazioni plausibili è la presenza del medesimo sfondo in tutte le immagini, che rende più difficile l’emergere delle caratteristiche distintive degli oggetti.
La classificazione
Una volta ultimato il training, nel menù dei blocchi della Teachable Machine ne compaiono tre nuovi: il blocco recognition result che restituisce in ogni momento il nome della categoria individuata dalla rete neurale per l’immagine proveniente dalla webcam; il blocco confidence of che consente di selezionare una categoria e restituisce il livello di confidenza, ovvero una percentuale di quanto sia plausibile che l’immagine inquadrata possa essere ascritta alla categoria selezionata; il blocco recognition result is che consente di selezionare una categoria e restituisce il risultato del riconoscimento, vale a dire che controlla se l’immagine inquadrata possa essere ascritta alla categoria selezionata e restituisce VERO in caso affermativo, altrimenti restituisce FALSO.
Con questi blocchi è possibile utilizzare la rete neurale per interagire con gli altri comandi, integrando le possibilità di questi modelli di machine learning nei propri progetti.
Per approfondire
- Intelligenza artificiale con mBlock
Un webinar in cui viene introdotta la storia dell’Intelligenza Artificiale fino agli sviluppi recenti e viene poi illustrato l’utilizzo della Google Teachable Machine attraverso mBlock. - L’anno dell’Intelligenza Artificiale
Un articolo su alcune recenti conquiste nel campo dell’Intelligenza Artificiale. - Experiments with Google | Teachable Machine
Alcuni progetti sperimentali realizzati con l’impiego della Teachable Machine di Google. - Come implementare modelli addestrati di AI su mBlock
Una guida che illustra come eseguire i passaggi descritti in questo articolo per utilizzare mBlock e la Teachable Machine.